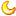|
|
这是scrapy中的源码 该项目只爬一样调试
scrapy
json
requests
time
..items HousingresourcesspiderItem
..settings *
FsfcSpider(scrapy.Spider):
name = allowed_domains = []
p = start_urls = [.format(p)]
bulid_url = house_api = room_url =spider_time = time.strftime(,time.localtime(time.time()))
get_total():
parse(,response):
.p ==:
build_ids = response.xpath().extract()
build_ids:
build_id build_ids:
DEFAULT_REQUEST_HEADERS[] = +(.p)
scrapy.Request(
=.one_parse,
=.bulid_url.format(build_id),
=)
.p+=DEFAULT_REQUEST_HEADERS[] = +(.p-)
scrapy.Request(
=.parse,
=+(.p),
= )
(% (.p-))
one_parse(,response):
item = HousingresourcesspiderItem()
project_name = response.xpath().extract_first()
project_name :
item[] =project_name.strip() :
item[] = project_area = response.xpath().extract_first()
project_area :
item[] =project_area.strip() :
item[] = property_deverloper = response.xpath().extract_first()
property_deverloper :
item[] = property_deverloper.strip() :
item[] = admini_area = response.xpath().extract_first()
admini_area :
item[] = admini_area.strip() :
item[] = gurls = response.xpath().extract()
builds = response.xpath().extract()
gurl,build (gurls,builds):
DEFAULT_REQUEST_HEADERS[] = gurls
gurl = +gurl
item[] = build
scrapy.Request(
=.one_page,
=gurl,
={:item},
=,
)
one_page(,response):
item = response.meta[]
bid = response.url.split()[-]
scrapy.Request(
=.one_page_json,
=.house_api.format(bid),
=,
={:item}
)
one_page_json(,response):
item = response.meta[]
room_list = json.loads(response.text)
room room_list:
item[] = room[] item[] = room[] item[] = room[] item[] = room[]item[] = room[]item[] = room[]rid = room[]
DEFAULT_REQUEST_HEADERS[] = .room_url.format(rid)
scrapy.Request(
=.two_page,
=.room_url.format(rid),
=,
={:item}
)
two_page(,response):
DEFAULT_REQUEST_HEADERS[] = response.url
item = response.meta[]
selling_prices = response.xpath().extract_first().strip()
selling_prices selling_prices[] ==selling_prices == :
selling_prices = item[] = selling_prices
item[] = .spider_time
item
(item)
第一个问题:
像这样我开始运行后要过两三分钟数据才会开始跑,要怎样才能解决,
第二个问题:
开始运行后一些数据总会重复很多次像:
这样的话程序就要很久才能停止 。请问以上的问题是什么原因,要怎么解决?
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
x
|