|
|
废话不多说,直接开干~
吸取了百度精华,来写文章了!
难度系数:两颗星
大概逻辑:
1.请求url
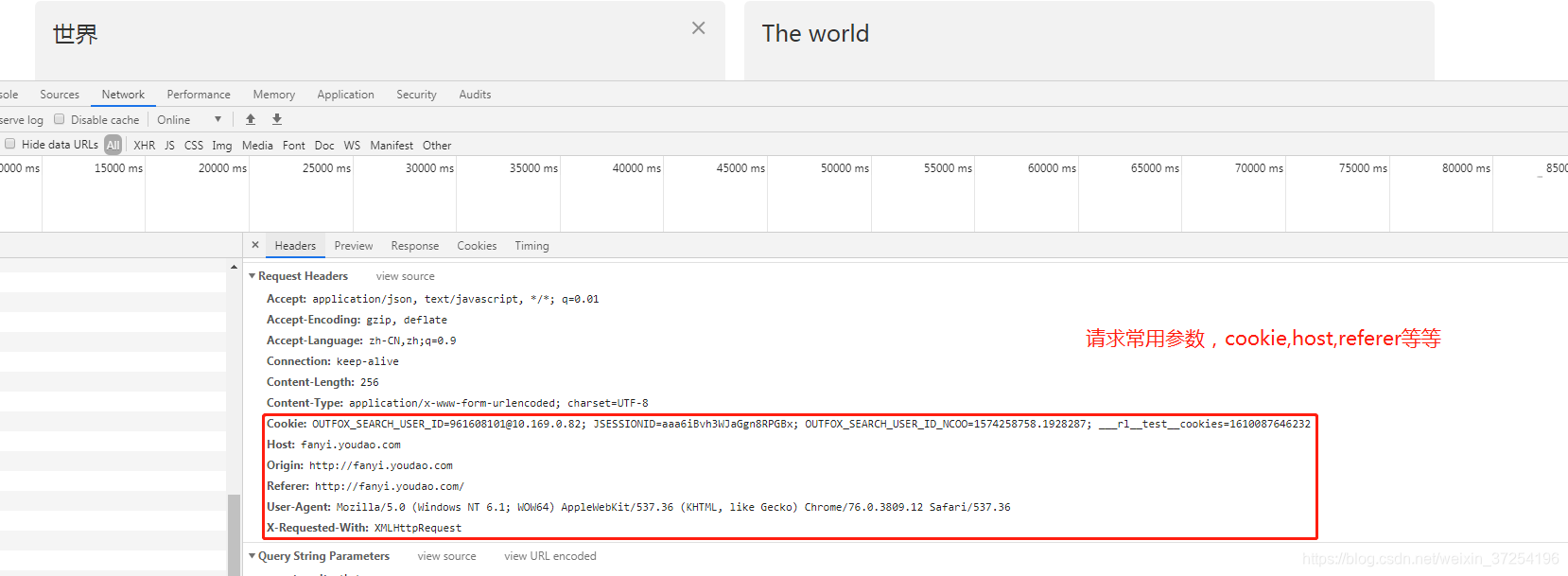
2.找到请求参数
3.分析参数产生过程
4.整合参数
1.请求url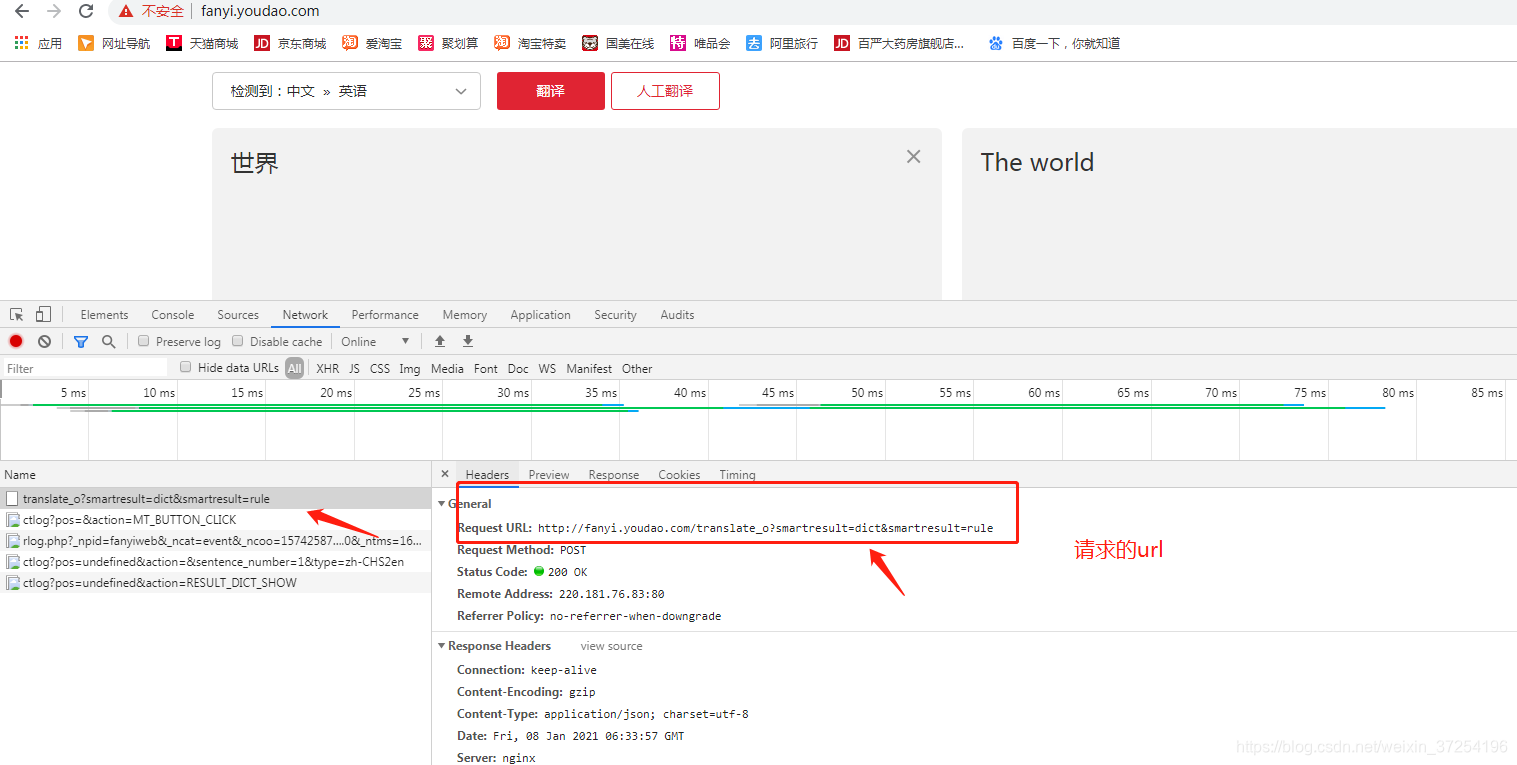
2.找到请求参数
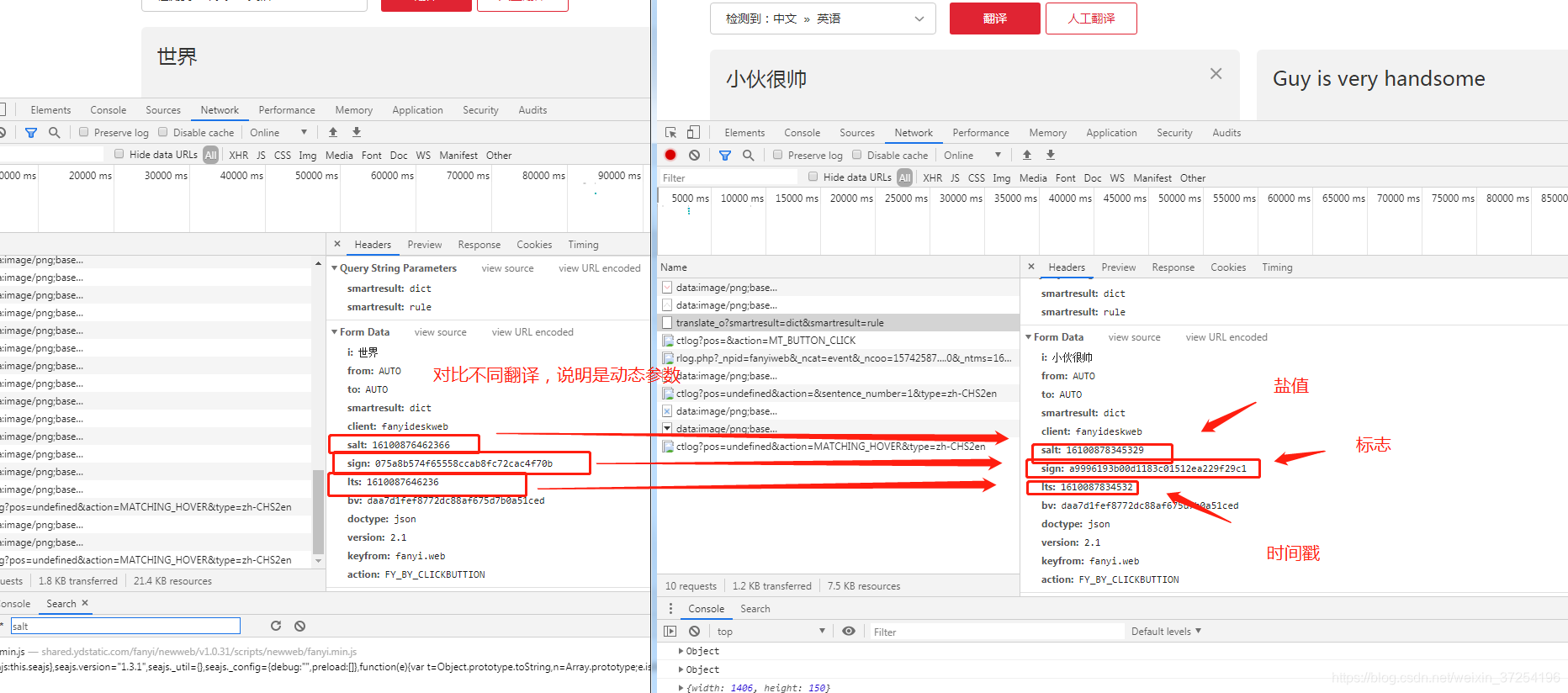
3.分析参数产生过程
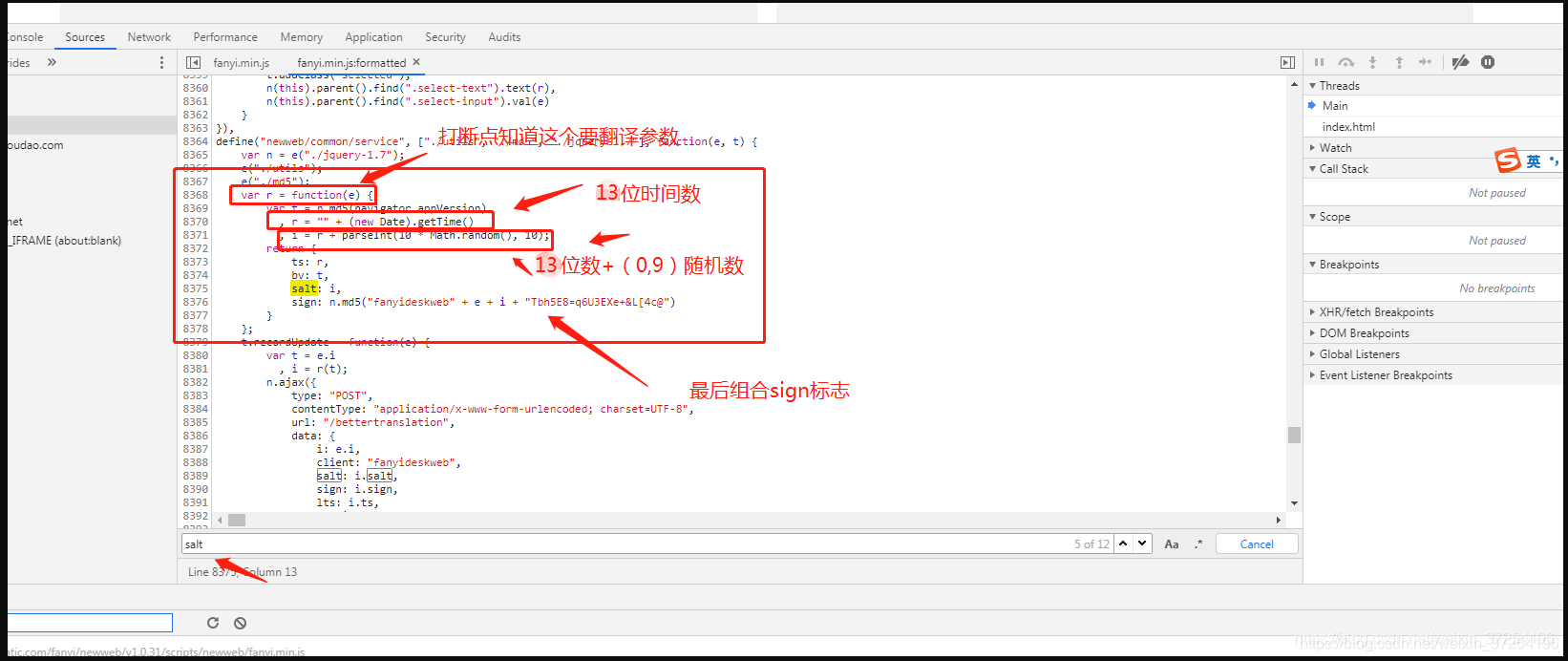
e: 输入的要翻译的内容。
ts: 当前时间戳字符串 [13位]salt: 时间戳字符串拼接上0-9 的随机整数。
bv: 将 User-Agent 经过 md5 加密之后的密文
sign: 将 “fanyideskweb” + e + i + "Tbh5E8=q6U3EXe+&L[4c@"经过 md5 加密之后的密文。12345
4.整合参数
直接上代码
# -*- coding:UTF-8 -*-import randomimport timeimport hashlibimport requestsclass YoudaoCrawl(object):
def __init__(self, word):
"""初始化方法"""
self.url = " http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule"
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36",
"Cookie": '[email protected]; JSESSIONID=aaa6iBvh3WJaGgn8RPGBx; OUTFOX_SEARCH_USER_ID_NCOO=1574258758.1928287; ___rl__test__cookies=1610087834528',
"Referer": "http://fanyi.youdao.com/"
}
self.word = word
self.post_body = {}
def genrator_post_body(self):
"""生成请求体字典方法"""
# 1:拿到13位的时间戳
ts = str(int(time.time()*1000))
# 2: 得到salt = 13位时间戳+1位随机值
salt = ts + str(random.randint(0, 10))
# 3: 得到sign = 两个字符串 + 被翻译的值 + 盐值
sign_str = "fanyideskweb" + self.word + salt + "Tbh5E8=q6U3EXe+&L[4c@"
# 4: 将sign_str 用md5进行加密:
md5 = hashlib.md5()
md5.update(sign_str.encode())
sign = md5.hexdigest()
self.post_body = {
"i": self.word,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": sign,
"ts": ts,
"bv": "b286f0a34340b928819a6f64492585e8",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME"
}
def send_request(self):
"""发送请求的方法"""
response = requests.post(self.url, headers=self.headers, data=self.post_body)
return response.json()
def parser_response(self, ret_dict):
# 从字典中提取翻译结果
# jsonpath: $..src
ret = ret_dict["translateResult"][0][0]["tgt"]
print("翻译的文本:{} 翻译的结果:{}".format(self.word, ret))
def run(self):
"""运行函数"""
self.genrator_post_body()
ret_dict = self.send_request()
self.parser_response(ret_dict)if __name__ == '__main__':
data = input("请输入参数:")
spider = YoudaoCrawl(data)
spider.run()123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869
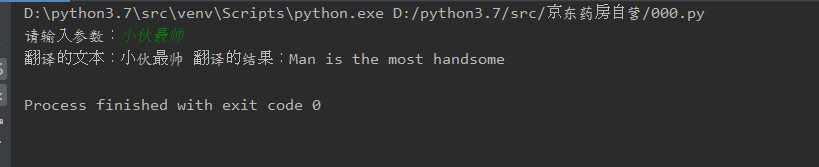
运行结果:
公众号:

|
|

